Choosing the wrong AI architecture costs more than money - it costs time, user trust, and competitive ground. Yet many product teams default to the most hyped option rather than the right one.
This playbook cuts through the noise. It gives senior and aspiring product managers a clear, decision-driven guide to RAG, fine-tuning, and AI agents - when to use each, and how to combine them.
Core Concepts
Retrieval-Augmented Generation (RAG)
It is an AI framework that improves Large Language Model (LLM) accuracy by retrieving data from external, trusted sources like company documents or databases before generating a response.
Example: A customer support bot that fetches your latest product documentation before answering a user's question - ensuring the answer is current and grounded in your actual content.
Fine-Tuning AI Models
Fine-tuning trains a pre-trained model on your custom dataset, to improve performance for a particular task, style, or domain.
Example: A legal tech company fine-tunes a model on thousands of contract review examples so it consistently identifies clause types using the firm's preferred terminology.
AI Agents
AI agents go beyond generating text - they plan, take action, and complete multi-step tasks autonomously. They use tools (web search, APIs, code executors) and often operate in loops until a goal is achieved.
Example: A sales agent that researches a lead, drafts a personalized email, schedules a follow-up, and logs everything in a CRM - all without human intervention.
Key Differences
| Dimension | RAG | Fine-Tuning | AI Agents |
| Knowledge source | External (retrieval) | Baked into weights | Dynamic (tools + memory) |
| Setup cost | Low–Medium | High | Medium to High |
| Latency | Medium | Low | High |
| Adaptability | High (update docs) | Low (retrain needed) | Very High |
| Best for | Current, factual Q&A | Style/task consistency | Multi-step automation |
| Failure mode | Bad retrieval = bad answers | Overfitting, data leakage | Runaway loops, tool errors |
When to Use RAG ?
Decision Criteria
- Your product needs up-to-date or domain-specific knowledge (e.g., policies, docs, inventory)
- The knowledge base changes frequently
- You need source attribution or citations
- Fast deployment matters more than model consistency
Example
An internal HR chatbot that answers employee questions about the latest benefits policy. The policy changes quarterly - RAG keeps answers accurate without retraining.
Pros & Cons
Pros:
- Fast to deploy; no model retraining
- Transparent sourcing; easy to audit
- Knowledge can be updated independently of the model
Cons:
- Retrieval quality directly affects output quality
- Requires strong chunking and embedding strategy
- Poor semantic search = irrelevant context = hallucinated answers
When to Use Fine-Tuning ?
Decision Criteria
- You need the model to consistently follow a specific format, tone, or schema
- You have high-quality labeled data (1,000+ examples minimum)
- Latency is critical and repeated prompting is too slow
- The task is narrow and well-defined
Example
A medical documentation tool that converts physician voice notes into structured SOAP notes. The format is rigid, the vocabulary is specialized, and fine-tuning on existing notes produces far superior consistency than prompting alone.
Pros & Cons
Pros:
- Highest consistency on narrow, well-defined tasks
- Faster inference once deployed (no retrieval overhead)
- Embeds institutional vocabulary and patterns into the model
Cons:
- Requires significant labeled data and compute to train
- Knowledge becomes stale - model needs retraining as the world changes
- Risk of overfitting if training data lacks diversity
When to Use AI Agents ?
Decision Criteria
- The task involves multiple steps, tools, or decision branches
- Automation across systems is required (CRMs, databases, APIs)
- The workflow benefits from dynamic planning - the path isn't fixed in advance
- Human-in-the-loop can be incorporated for oversight
Example
An e-commerce operations agent that monitors inventory, identifies low-stock SKUs, checks supplier lead times via API, and drafts purchase orders for human approval - all triggered by a daily schedule.
Pros & Cons
Pros:
- Handles complex, multi-step workflows end-to-end
- Highly flexible; adapts based on tool results
- Can dramatically reduce manual operational overhead
Cons:
- Harder to debug; failure can cascade across steps
- Higher latency and infrastructure complexity
- Requires robust error handling, retries, and human oversight guardrails
Hybrid Approaches
In practice, the most powerful AI products combine all three. The goal is to use each approach where it plays to its strength.
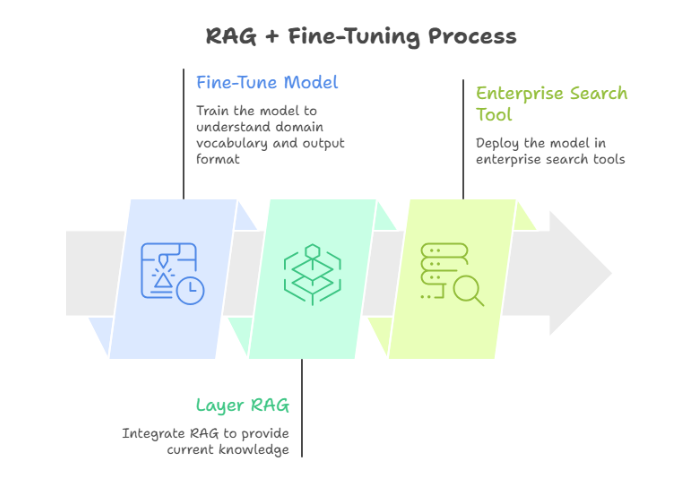
Pattern 1: RAG + Fine-Tuning
Fine-tune the model to understand your domain vocabulary and output format, then layer RAG for current knowledge. Used in enterprise search tools where both terminology precision and fresh content matter.
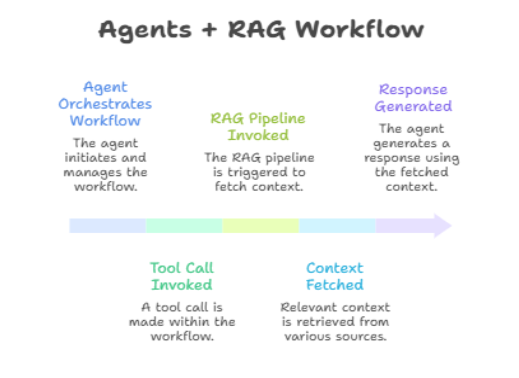
Pattern 2: Agents + RAG
An agent orchestrates a workflow; each tool call may invoke a RAG pipeline to fetch relevant context before generating a response. Common in AI research assistants that need to browse, retrieve, and synthesize across sources.
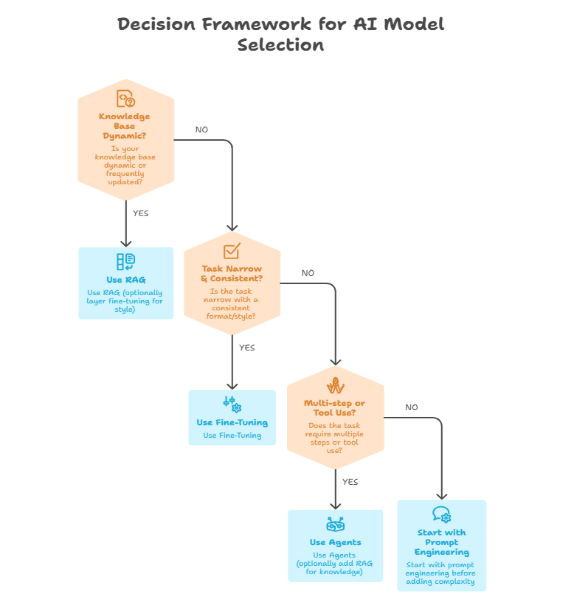
Decision Framework
Use this quick decision tree before choosing your architecture:
Cost, Performance, and Scalability
| Consideration | RAG | Fine-Tuning | Agents |
| Upfront cost | Low | High (data + compute) | Medium |
| Ongoing cost | Retrieval + inference | Inference only | High (multiple calls) |
| Scalability | High | High | Medium (orchestration overhead) |
| Time to production | Days to weeks | Weeks to months | Weeks |
For early-stage products, RAG offers the fastest path to value. Agents are best introduced after core workflows are mapped and edge cases are understood.
Common Pitfalls
Fine-tuning too early. Teams reach for fine-tuning before testing whether a well-engineered prompt solves the problem. Prompt engineering is free; fine-tuning is not.
Ignoring retrieval quality in RAG. A RAG system is only as good as its chunking, embedding, and ranking strategy. Poor retrieval = confident but wrong answers.
Building agents without fallback logic. Agents fail in production when a tool returns an unexpected response. Without retry logic and graceful degradation, one API error can break the entire workflow.
Over-indexing on model performance. Product teams often obsess over benchmark scores and ignore system design. Architecture decisions matter more than model choice for most use cases.
Best Practices
- Define the task precisely before choosing an architecture. Vague goals produce vague architectures.
- Version your fine-tuning datasets. Data quality degrades silently; treat training data like production code.
- Start agents small. Build single-tool agents first, validate reliability, then expand the tool set.
Build evaluation pipelines early. Manual testing doesn't scale. Automated evals catch regressions before users do.
Future Trends
Three directions will define AI product architecture in the near term:
- Long-context models reduce RAG's necessity - but not eliminate it. Cost and focus still favor retrieval for large corpora.
- Smaller, specialized fine-tuned models outperforming large general models for narrow tasks at a fraction of the cost.
- Agent reliability tooling maturing - better orchestration frameworks, built-in retry logic, and standardized evaluation are making agents safer for production deployment.
Conclusion
The best AI product decisions are context-driven, not hype-driven. RAG wins when knowledge is dynamic. Fine-tuning wins when consistency and task specificity matter most. Agents win when multi-step automation is the goal.
Start simple. Measure relentlessly. Layer complexity only when the data justifies it. That discipline is what separates AI products that ship from those that stall.
FAQ
Q1: What is the main difference between RAG vs fine-tuning vs agents?
RAG retrieves external knowledge at runtime; fine-tuning bakes knowledge and behavior into the model's weights through training; agents use tools and planning to complete multi-step tasks autonomously. Each solves a different class of problem.
Q2: When should I use RAG in my AI product?
Use RAG when your product requires up-to-date, domain-specific, or frequently changing information such as internal docs, product catalogs, or knowledge bases. It's the fastest and most auditable way to ground a model in your content.
Q3: Is fine-tuning AI models worth the cost?
Only if you have a narrow, well-defined task with high-quality training data and consistent formatting requirements. For most teams, RAG combined with prompt engineering delivers equivalent results at a fraction of the cost and time.
Q4: What are the best AI agents use cases in enterprise products?
High-value agent use cases include sales outreach automation, IT ticket triage and resolution, data pipeline monitoring, procurement workflows, and multi-source research summarization - anywhere a human currently performs repetitive multi-step tasks across systems.
Q5: Can you combine RAG, fine-tuning, and agents in one system?
Yes, and many production AI systems do. A common pattern is a fine-tuned model (for style and domain language) backed by a RAG pipeline (for current knowledge), orchestrated by an agent (for task completion). Start with one layer, validate it, then add complexity as needed.


.png&w=1200&q=75)