Let’s be honest: testing AI language models is… tricky.
With traditional software, you give it an instruction, and you get a clear, predictable answer, like pressing the “print” button and the printer printing your document exactly right every time.
But with Large Language Models (LLMs), you enter a prompt and wait nervously, hoping the response makes sense, and hoping it’s not wildly off, like mixing up names or facts in ways that confuse or mislead.
So how do you truly know if your AI-powered app performs reliably in the real world?
That’s where AI evaluations, “evals”, come in.
They are the invisible infrastructure that makes modern AI trustworthy, consistent, and production-ready.

The Real-World Pain of LLM Development
Anyone who has built with LLMs knows this pain:
- Inconsistent outputs - same input, different answers.
- Ambiguity triggers hallucination - even slight.
- Demos break instantly - when exposed to messy real-world data.
- Failure modes stay hidden - until users encounter them.
You can’t ship production AI systems on gut instinct.
Evals are the radar system that keeps your product from drifting into unreliability.
So… What Exactly Is an Eval?
An eval is a structured, repeatable process for measuring how well your AI system performs across different tasks and real-world situations.
Think of evals as your GPS:
They won’t eliminate every pothole, but they’ll alert you the moment you veer off course.
In practice, evals work as:
- Background checks - quietly flag anomalies in outputs.
- Guardrails - block or re-route risky or nonsensical responses.
- Improvement levers - highlight specific weaknesses so you can fix what matters.
Production-Grade Eval Methods Every Builder Should Know
1. Unit Evals (Microtests)
Small, focused tests for granular abilities like:
- entity extraction
- tone rewrite
- text → SQL
- summarization format checks
Useful for validating specific skills reliably.
2. Behavioral Evals
These test the model’s behavior in more complex environments:
- multi-step reasoning
- ambiguous prompts
- misleading or adversarial inputs
- edge-case sequences
This is where most real-world failures occur, and where evals create clarity.
3. Regression Evals
Whenever you tweak a prompt, swap a model, or adjust context windows, regression evals reveal what silently broke.
All top-tier AI companies run extensive regressions before every deployment.
4. Red-Team Evals
These deliberately try to break the system:
- jailbreak attempts
- biased or unsafe outputs
- factuality traps
- hallucination probes
Critical for enterprise-grade reliability.
5. Continuous Monitoring (Online Evals)
Live checks that monitor real user traffic for:
- drift
- anomalies
- growing error patterns
- degraded performance over time
This is your observability layer for production AI.
Why LLM Evaluation Is Hard: The Three Gulfs
Evaluating LLMs is uniquely challenging because of three gaps:
1. Unpredictable User Inputs
Real-world user messages are chaotic, unstructured, and surprising.
2. Fragility of Instructions
Models follow instructions literally, not your intention behind them.
3. Poor Generalization
Even perfect prompts break when data drifts beyond expected patterns.
Evals help you bridge these gaps with structure and discipline.
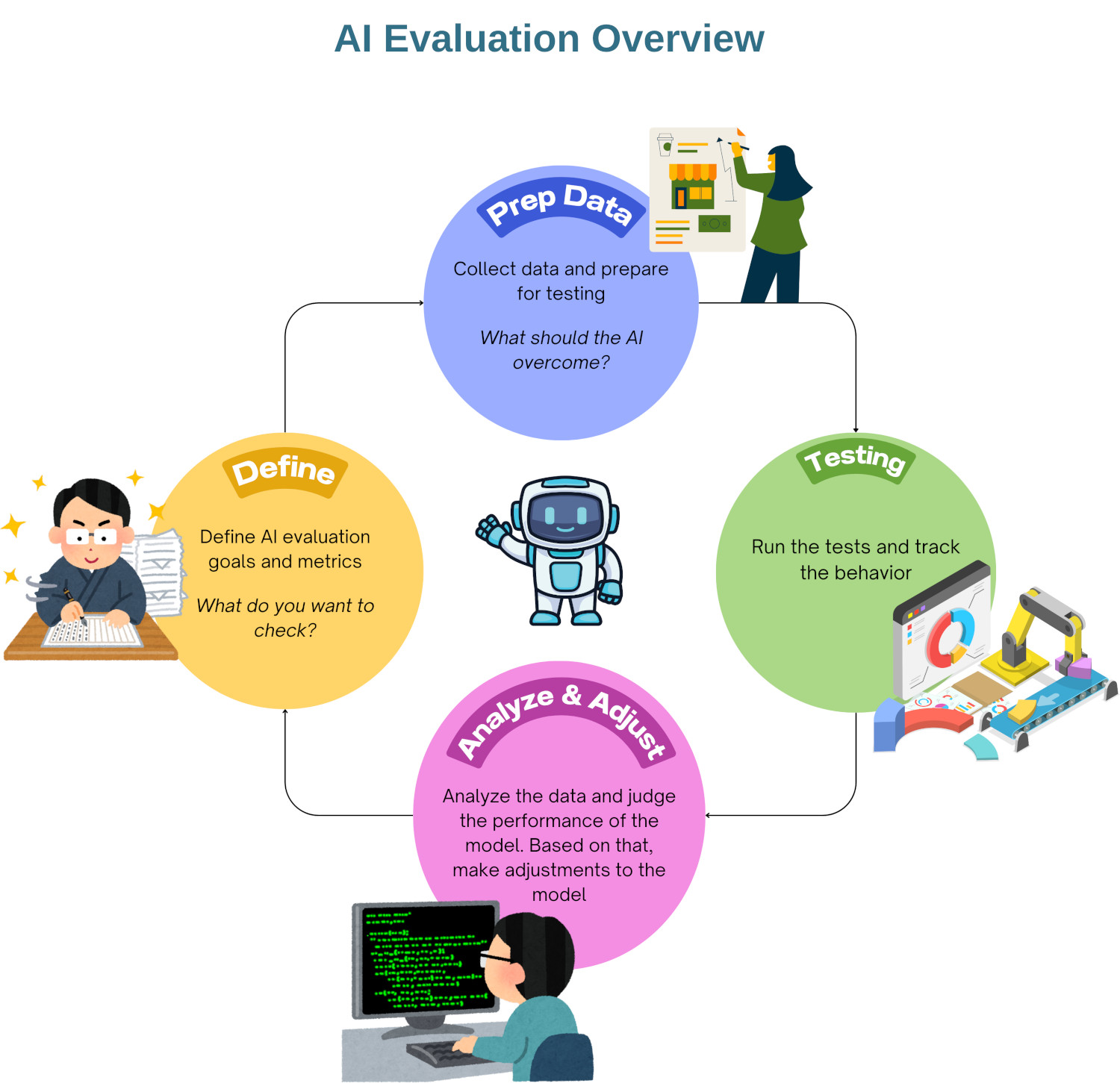
The Evaluation Lifecycle (A Practical Framework)
You don’t need a research team, just a tight iterative loop:
1. Analyze
Review outputs across examples; identify unusual or problematic patterns.
2. Measure
Convert fuzzy problems into measurable checks or rules.
3. Improve
Adjust prompts, refine logic, relabel data, or fine-tune.
4. Monitor
Track ongoing performance against real user interactions.
5. Iterate
Repeat - because your model and your users will keep evolving.
This lifecycle brings order to unpredictability.
Better Prompts = Better Evals
Great prompts aren’t discovered, they’re engineered.
Effective prompts usually include:
- Clear role & purpose
- Step-by-step instructions
- All necessary context
- Example inputs & outputs
- Strict output format instructions
- Structured delimiters
Manually iterating prompts before automating them helps you discover model quirks faster, and evaluate more precisely.
What Real Eval Cases Look Like in Senior AI Teams
High-performing teams test tasks such as:
1. Instruction Following
“Rewrite into exactly three bullet points. Max 12 words per bullet.”
2. Guardrail & Safety Checks
Attempt to induce biased, harmful, or unsafe responses.
3. Structured Extraction
“Output valid JSON only. Reject all extra commentary.”
4. Domain-Specific Tasks
From this contract, extract ‘governing law’ and ‘expiry date.
5. Failure Pattern Probes
Inputs crafted to target past known model weaknesses.
These make expectations measurable, and failures actionable.
Metrics That Matter
Reference-Based Metrics
Used when a “correct” answer exists.
Examples: semantic similarity, accuracy, grounding.
Reference-Free Metrics
Used for open-ended tasks.
Examples: relevance, safety adherence, format compliance.
Start with practical, binary checks, deeply effective early in the lifecycle.
Save complex scoring or AI-judge models for stubborn or nuanced failure patterns.
Tools That Make Evals Easier
Industry-leading teams commonly use:
- OpenAI Evals - structured YAML/JSON definitions
- Ragas - evaluation for RAG systems
- TruLens - feedback-based evals for LLM pipelines
- LangSmith - prompt tracing + evaluation workflows
- DeepEval - human + AI judging
- Phoenix (Arize) - observability + drift detection
These tools help you avoid reinventing the wheel and standardize your workflow.
Advanced Metrics Elite AI Teams Track
If you want to evaluate AI like OpenAI, Anthropic, or Meta, consider:
- Factual Consistency (FactScore / Faithfulness / QAGS)
- Hallucination Rate
- Groundedness
- Latency & Throughput
- Win Rate (A/B comparisons)
- Chain-of-Thought Quality (for internal debugging)
These metrics separate hobby projects from production systems.
Why Custom Evals Beat Leaderboards
Leaderboard scores (MMLU, GPQA, BIG-Bench) don’t reflect your domain, your users, or your business.
The only scores that matter:
The ones you design for your real tasks, with your data.
Simple Judgments Are Powerful
Don’t overcomplicate evaluation.
When in doubt:
- Binary > subjective ratings
- Win/loss > star scores
- Checklists > narratives
Evals are about clarity - not complexity.
It’s a wrap.
If you want to build AI products that last, not just flashy demos, invest in evals.
They are iterative, often messy, but undeniably powerful.
Evals are the dividing line between:
“It sorta works.” → “It works every time.”


.png&w=1200&q=75)